클러스터 성능 최적화
개요
대규모 쿠버네티스 클러스터를 운용하게 되면 다양한 부분에서 트래픽 지연, 성능 저하 등의 문제가 발생할 수 있다.
이 문서에서는 어떤 부분에서 부하가 발생할 수 있고, 어떤 해결책들이 있는지 전체적으로 총괄하여 알아본다.
먼저 공식 문서에서 클러스터의 규모에 대해 권고하는 사항이 몇 가지 있다.[1]
한 클러스터에서 최대,
- 한 노드에 파드 110개
- 노드 5000개
- 전체 파드 150,000개
- 전체 컨테이너 300,000개
이렇게 권고하지만, 막상 보면 이 이상으로 해도 괜찮은 경우도 있고, 오히려 최대 권고 사항에 도달하기도 전에 문제가 생기기도 한다.
결국 어디에서 병목이 발생하고 성능에 제약이 갈 수 있는지 파악하는지 구조를 파악하는 것이 중요하다.
API 서버의 부하
컨트롤 플레인의 동작에서 부하가 가장 많이 일어나는 구간은 어쩌면 당연하지만 kube-apiserver, Etcd이다.
이에 대해 정말 잘 정리된 글이 있다.[2] 존경합니다 선배님
파드에 대해 100개, 10000개 조회 요청을 보낼 때 시간을 비교하면 다음과 같다.
> curl -o /dev/null -s -w 'Total: %{time_total}s\n' 127.0.0.1:8001/api/v1/pods?limit=100
Total: 0.031002s # 31ms
> curl -o /dev/null -s -w 'Total: %{time_total}s\n' 127.0.0.1:8001/api/v1/pods?limit=10000
Total: 2.131027s # 2,131ms (100개대비 약 70배)
api 서버는 요청을 받고, etcd에 range api를 날려 데이터를 받아낸다.
이때 시간이 오래 걸리는 건 당연한 수순인데, 가장 걱정하고 고려해야 할 지점은 메모리이다.
먼저 api 서버에서 일어나는 작업을 보자.
api 서버는 읽기 요청을 처리하는데 굉장히 많은 메모리를 사용한다.[3]
구체적으로 조회 작업은 다음의 순서를 거친다.
- etcd로부터 protobuf 형식의 데이터를 가져와 메모리 적재
- 데이터를 역직렬화하여 Go 구조체로 메모리 적재
- 클라이언트가 요청한 형식에 맞춰 데이터 가공
이 작업을 기본으로 하고 리스트 조회였다면 리스트 리소스로 바꾸고, 버전 변환 등의 작업이 들어가기도 한다.
결과적으로 한 요청을 처리할 때 api 서버는 메모리 100메가 가량을 순간 사용한다.
요청이 처리되고 가비지 컬렉팅이 되겠지만 요청이 몰리는 상황이라면 메모리 자원은 금새 고갈될 수 있다.
최대 요청량 제한
api 서버가 감당하는 부하 자체는 --max-requests-inflight, --max-mutating-requests-inflight를 통해 어느 정도 해소할 수 있다.
이는 말 그대로 들어오는 읽기 요청, 쓰기 요청의 전체 제한을 걸어 초과하는 요청을 버린다.
주기성 요청의 경우 한두 번 버려진다고 해도 그리 문제는 되지 않을 가능성이 높다.
하지만 높은 트래픽 부하가 발생하는 순간에 좋은 해결책이라고 보기는 당연히 힘들다.
요청에도 중요도가 저마다 다르기에, 일괄적인 제한은 클러스터 관리에 치명적인 결과를 초래할 수도 있다.
그래서 쿠버네티스에서는 API Priority and Fairness라는 개념으로 더 정제된 방식으로 요청 제한을 할 수 있도록 지원한다.[4]
다만 이 방식은 중간 로직을 삽입한 꼴이기 때문에 메모리 부하에 있어서는 그다지 도움이 되지는 않는다.
또한 APF는 api 중 watch 요청에 대해서만 작동하는데, 이에 맞춰 쿠버네티스에서는 버전 업그레이드를 하면서 점차 List 요청을 Watch로 바꾸는 방향으로 성능 개선을 이뤄내고 있다.
적게 요청하기
부하는 보통 요청에 대한 응답 프로세스가 길고 데이터가 크거나, 혹은 요청이 많을 때 발생한다.
이를 클러스터 환경에 맞춰 표현하면 다음과 같은 상황을 말한다.
- 파드가 많음 - 잡이 많이 돌아 쓰지도 않는 종료 파드가 많다면 응답할 리소스가 많아진다.
- 노드가 많음 - kubelet, kube-proxy, CNI 에이전트 같이 지속적으로 api 서버에 요청하는 개체가 많아진다.
이런 상황에서는 사용되지 않는 파드, 불필요한 노드를 줄이는 것이 가장 좋다.
그러나 여의치 않다면 조금이라도 요청을 효율적으로 보내는 것도 하나의 방법이다.
먼저 파드가 많은 상황에서는 필요한 데이터만 가져올 수 있도록 요청을 보내는 방법이 유효하다.
다음은 kubectl에서 날아가는 요청의 예시이다.
GET https://127.0.0.1:6443/api/v1/namespaces/default/pods?continue=eyJ2IjoibWV0YS5rOHMuaW8vdjEiLCJydiI6MzkzNDcsInN0YXJ0IjoidGVzdC01NzQ2ZDRjNTlmLTJuNTUyXHUwMDAwIn0&limit=500
위와 같이 limit, continue(어디서부터 조회를 시작할지)을 걸어 조회할 범위를 아예 줄여버리면 부하가 상대적으로 덜하다.
다음으로 노드가 많은 상황에서는 에이전트의 요청 주기를 줄이는 것이 하나의 방법이 된다.
어쩌면 당연하겠지만 api 서버로 들어가는 다수의 요청은 사람이 만들어내기보다는 다른 에이전트, 컴포넌트에서 발생한다.
대표적으로 다음의 요소들의 api 요청 현황을 검토하고 요청 주기를 조절하는 시도가 유효하다.
- kubelet, kube-proxy 등의 기본 컴포넌트
- CNI 에이전트, 로깅이나 메트릭을 수집하는 관측 가능성 에이전트
- 데몬셋으로 배치되는 경우 노드의 개수만큼 트래픽을 발생시킨다.
ETCD의 부하
Etcd는 데이터베이스인 만큼, 데이터 일관성을 매우 중시하고, 그만큼 상당히 메모리를 많이 소모한다.
트랜잭션을 처리하는 동안 etcd는 일관성을 위해 락을 건 후에 응답할 데이터를 메모리에 두는데 이때 메모리 사용량이 늘어난다.
저장된 데이터를 protobuf 형태로 만들 때 상당한 자원을 소모하고, 심지어 etcd는 범위 조회 api만을 가지고 있어 자칫하면 어마무시하게 많은 양의 데이터를 메모리에 적재하게 되는 수가 있다.
당연하지만 etcd의 부하는 다른 것보다 훨씬 심각성이 크다.
api 서버는 그저 웹 서버에 불가하기에 얼마든지 스케일링이 가능하다.
그러나 etcd는 고도의 일관성을 위해 HA 구성을 하더라도 RAFT 기반으로 동작하여 단 하나의 리더 노드만이 존재하게 된다.
로드밸런싱을 해도 팔로워 노드들은 받은 트래픽을 리더 노드로 넘기기 때문에 결국 스케일링으로 얻는 효과가 고가용성 향상 뿐이다.
쓰기 속도가 준수한 스토리지를 사용하는 것은 도움이 되나, 노드 1000대가 넘어가는 클러스터 환경에서는 단순히 스펙을 올리는 것만으로는 불충분할 수 있다.[5]
(범지구적 트래픽은 감당하는 OpenAI 사례라는 점은 참고하자)
일관성 양보하기
api 서버에서 요청을 보낼 때마다 etcd 부하는 커지는 법이다.
그래서 이 요청 자체를 줄이는 것이 유효한 선택지인데, 간단하게 api 서버에 캐싱된 내용을 활용하면 된다.
메타데이터에서 resourceVersion을 0으로 요청하면, api 서버는 etcd가 아니라 캐시에서 데이터를 꺼내온다.
당연히 이는 어느 정도의 데이터 일관성은 포기하는 방식이지만, watch 매커니즘으로 동작하는 컴포넌트들이 있기 때문에 막상 보면 캐시에 나름 최신 데이터가 들어가긴 한다.
이 방법은 api 서버에 대한 부하는 줄어들지 않으나, 최소한 api 서버는 stateless하기 때문에 부담이 덜하다.
event api 분리
Event api는 별도의 etcd 클러스터를 두고 운영하면 메인 etcd의 부하가 줄어들어 유용하다.
--etcd-servers-overrides=/events#https://0.example.com:2381;https://1.example.com:2381;https://2.example.com:2381
이런 식으로 옵션을 넣어주면 자주 발생하는 event 정보를 따로 관리할 수 있다.
이 방식은 etcd의 전체 용량을 개선하는 데에도 도움이 된다.
etcd의 스토리지는 기본 2기가를 사용하고, --quota-backend-bytes를 통해 최대 8기가까지 늘릴 수 있다.[6]
이 이상으로 넘어가면 성능이 급격하게 떨어지기에[7], 용량 초과 시 etcd는 쓰기가 불가능한 상태가 된다.[8]
데이터가 많이 발생하면서 로그성인 event를 별도로 관리하는 것은 etcd 관리에 매우 큰 도움이 된다.
버전 업그레이드
쿠버네티스는 지금도 활발히 개발이 되고 있으며, 기능적인 추가 뿐 아니라 성능 최적화 측면도 계속 개선되고 있다.
etcd 3.6.0 버전에서는 메모리 소모에 50퍼 절감이라는 비약적인 개선이 이뤄졌다.[9]
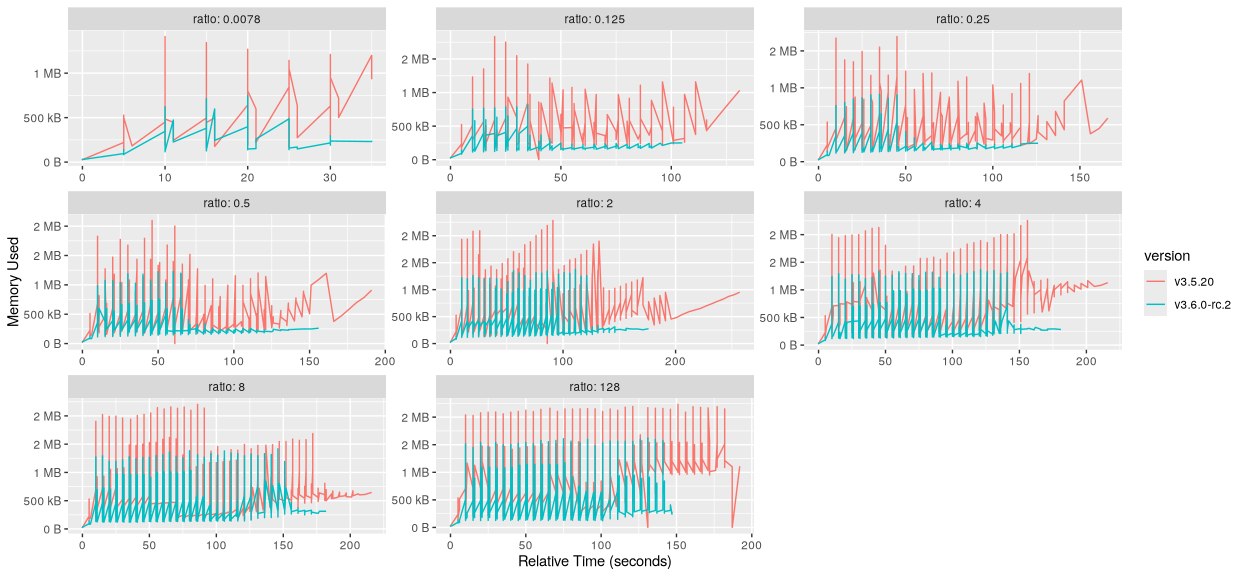
이는 스냅샷 히스토리 유지량을 10만개에서 만개로 줄이고, raft 히스토리를 더 자주 압축하여 이뤄진 성과이다.
여기에 처리량 역시 여러 업그레이드를 거치며 10퍼센트 가량 개선됐다.
Core DNS 최적화
CoreDNS는 클러스터의 모든 도메인 질의를 담당하는 만큼 워크로드가 늘어나면 부하도 늘어나게 된다.
이때 단일 소켓으로 요청이 폭주하면 필연적으로 드랍되는 요청이 생기기 마련인데, 이를 완화하는 방법 중 하나로 멀티 소켓 플러그인을 사용할 수 있다.[10]
. {
multisocket 5
forward . /etc/resolv.conf
}
일반적인 서버는 하나의 리스닝 소켓으로 통신한다.[11]
이 소켓에는 하나의 포트가 바인딩되고, 서버가 리스닝 상태인 채 여러 요청이 들어올 때 이 리스닝 소켓에 1:N 매핑되는 복수의 액셉트 소켓이 생성되어 통신을 수행하는 방식이다.
커널이 3.9 버전 이상이면, SO_REUSEADDR, SO_REUSEPORT을 통해 여러 리스닝 소켓을 하나의 포트에 바인딩하는 것이 가능해진다.
(참고로 SO_REUSEADDR은 여러 소켓을 바인딩하는 것을 가능하게 하는 것은 맞는데, 외도치 않은 서버 재시작 시 TCP TIME_WAIT으로 인해 소켓 바인딩이 실패하는 것을 막기 위해 쓰인다.[12][13])
멀티 소켓 플러그인은 바로 SO_RESUSEPORT를 사용하는데, 이 인자 커널 단에서 소켓 그룹을 만들어 하나의 IP+PORT에 대해 여러 리스닝 소켓을 바인딩할 수 있도록 해준다.
그럼 이 여러 소켓에 각각 스레드나 프로세스를 매핑시켜 요청을 처리할 수 있어 멀티 CPU 환경에서 연산 자원 활용도를 높이고 처리 성능을 최적화할 수 있게 되는 것이다.[14]
커널 내부에서는 inet_lookup_listner() 함수에서 관련 동작을 처리하는데, (srcIP, srcPort, dstIP, dstPort) 튜플 기반 해싱을 통해 세션 일관성을 유지시킨다고 한다(gpt 피셜).
그러나 명확하게 자원이 얼마일 때 얼마나 QPS와 부하가 개선되는지는 환경마다 테스트가 필요하다.
대체로는 다음 정도를 예시로 들고 있다.
- CoreDNS가 CPU 4개를 소비하고 8개가 가능하다면
NUM_SOCKETS를 2로 설정 - CoreDNS가 CPU 8개를 소비하고 64개가 가능하다면
NUM_SOCKETS를 8로 설정
25년에 진행된 kubecon에선 아래와 같은 QPS 개선이 있었다고 이야기한다.[15]

네트워크 부하
클러스터가 커지면 그에 따라 당연히 통신량도 늘어난다.
늘어난 통신량을 처리하기 위해 더 좋은 스펙의 회선과 장비를 이용하는 것은 좋지만, 그럼에도 커널이나 어플리케이션 단에서 조치를 해줘야 하는 상황이 있을 수 있다.
노드 환경에 따라 다르지만 같은 대역 노드가 지나치게 많으면 맥 주소 테이블 캐싱이 불가능해질 수 있다.
이는 ARP 실패를 야기할 수 있기에, 커널 파라미터를 수정하는 것이 방법이 된다.
net.ipv4.neigh.default.gc_thresh1 = 80000
net.ipv4.neigh.default.gc_thresh2 = 90000
net.ipv4.neigh.default.gc_thresh3 = 100000
컨테이너 이미지 부하
이건 대규모 클러스터에서 발생하는 이슈는 아니고, 그저 운영 팁 중 하나라고 보면 되겠다.
용량이 큰 이미지를 다룰 때, 이미지를 받는 작업이 실패할 수 있다.
--serialize-image-pulls는 기본값이 참인데 이는 이미지를 순차적으로 pull 받도록 만들어 대용량 이미지에 의해 다른 이미지 pull이 지연될 수 있다.
이 설정을 끄려면 컨테이너 스토리지 드라이버가 overlay2로 설정돼 있어야 한다.
--image-pull-progress-deadline의 제한을 늘려 타임아웃이 발생하지 않도록 대비하는 것도 필요하다.
컨트롤 플레인 모니터링
컨트롤 플레인에 발생하는 부하를 측정하는 중요 메트릭과 쿼리에 대한 소개가 담긴 문서를 참조하자.[16]
https://kubernetes.io/docs/concepts/cluster-administration/flow-control/
하위 문서
| 이름 | is-folder | index | noteType | created |
|---|---|---|---|---|
| 컨트롤러 | - | - | knowledge | 2024-09-12 |
| CRD | - | - | knowledge | 2024-09-14 |
| API Aggregation Layer | false | - | knowledge | 2024-12-29 |
| CNI | true | - | knowledge | 2025-01-08 |
| kubeconfig | false | - | knowledge | 2025-01-13 |
| 설치 | false | - | knowledge | 2025-01-14 |
| CRI | true | - | knowledge | 2025-02-24 |
| CEL | false | - | knowledge | 2025-03-17 |
| 쿠버네티스 API 구조 | false | - | knowledge | 2025-03-19 |
| 오브젝트 | true | 0 | knowledge | 2024-12-23 |
| 코어 컴포넌트 | true | 0 | knowledge | 2025-03-19 |
| 클러스터 성능 최적화 | false | 13 | knowledge | 2025-08-30 |
| API Priority and Fairness | false | 14 | knowledge | 2025-08-30 |
관련 문서
EXPLAIN - 파생 문서
| 이름0 | related | 생성 일자 |
|---|
기타 문서
Z0-연관 knowledge, Z1-트러블슈팅 Z2-디자인,설계, Z3-임시, Z5-프로젝트,아카이브, Z8,9-미분류,미완| 이름0 | 코드 | 타입 | 생성 일자 |
|---|
참고
https://kubernetes.io/docs/setup/best-practices/cluster-large/ ↩︎
https://kubernetes.io/blog/2024/12/17/kube-apiserver-api-streaming/ ↩︎
https://kubernetes.io/docs/concepts/cluster-administration/flow-control/ ↩︎
https://aws.amazon.com/ko/blogs/containers/managing-etcd-database-size-on-amazon-eks-clusters/ ↩︎
https://www.reddit.com/r/learnpython/comments/utvxra/python_socketsol_socket_and_socketso_reuseaddr/?tl=ko ↩︎
https://wiki.terzeron.com/OS_일반_시스템/OS와_Network_일반/SO_REUSEPORT를_이용한_네트웍_서버_성능향상 ↩︎
https://www.redhat.com/en/blog/kubernetes-api-performance-metrics-examples-and-best-practices ↩︎